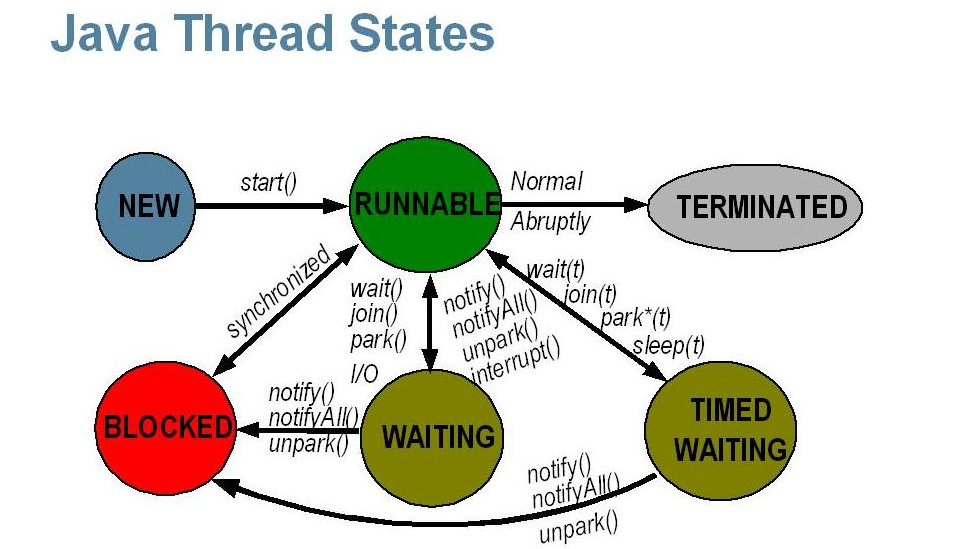
Бинарный поиск может существенно ускорить процесс поиска данных. Стоит отметить, что работает он только для предварительно отсортированного массива.
Суть алгоритма: необходимо разбить массив на две половины в середине. Проверить середину на совпадение с искомыми данными, если совпадение найдено завершить поиск, если искомое значение больше/меньше серединного, продолжить поиск в той или иной части массива рекурсивно.
Приступим к построению класса, который использует данный алгоритм.
Из библиотек нам особо ничего не понадобится…
#include <iostream> using namespace std;
Оприделим класс Search для поиска данных в массиве:
class Search{
private:
int *X;
int N;
public:
Search(int size) { X = new int[N=size];}
~Search() {delete [ ]X; }
void load_list(int input[ ]);
void show_list(char *title);
int binary_search(int S);
};
Теперь оприделим функции обозначенные в классе.
load_list — служит для загрузки массива в котором будет произведён поиск в наш класс. Тут всё просто, так что коментировать не буду…
void Search::load_list(int input[ ]){
for (int i=0;i<N;i++)
X[i] = input[i];
}
show_list — выводит на экран текстовую строку переданную в параметрах, а затем все члены массива поиска.
void Search::show_list(char *title){
cout << "\n" << title;
for (int i=0;i<N;i++)
cout << " " << X[i];
cout << "\n";
}
binary_search — занимается поиском данных переданный как параметр в определённом load_list массиве. Собственно именно в ней и находится всё ради чего делается остальное. Если совпадение найдено будет возвращён номер элемента, в противном случае — -1.
int Search::binary_search(int S){
int head;
int tail;
int middle;
int bmiddle;
int amiddle;
head = 0; //голова (начало) массива
tail = N; //хвост (конец) массива
/* !!! предполагается, что массив был отсортирован по возврастанию !!! */
if ((S < X[0]) || S > X[N-1]) return(-1); //т.к. массив отсортирован можно сразу оценить данные которые в него не входят
while(head<tail){
middle = ((head + tail)/2) + 1;
bmiddle = middle - 1;
amiddle = middle + 1;
/* проверяем середину и соседние ей ячейки */
if (S == X[middle] || S==X[bmiddle] || S== X[amiddle]) {
if (S==X[middle]) return(middle);
if (S==X[bmiddle]) return(bmiddle);
if (S==X[amiddle]) return(amiddle);
} else if (S>X[middle])
head = middle + 1;
else tail = middle - 1;
}
return(-1);
}
Ну и функция main для использования определённого класса:
int main(void) {
int search_key;
Search search_obj(10);
static int sorted_list[] = {2,5,10,31,45,48,52,58,66,82};
cout << "Бинарный поиск\n";
search_obj.load_list(sorted_list);
cout << "Что искать? "; cin >> search_key;
search_obj.show_list("Ищем в:");
int result = search_obj.binary_search(search_key);
if (result != -1)
cout << "Результат поиска: " << "X[" << result << "]=" << search_key;
else cout << "Результат не найден.\n";
return 0;
}
Вывод программы имеет такой вид:
Бинарный поиск Что искать? 2 Ищем в: 2 5 10 31 45 48 52 58 66 82 Результат поиска: X[0]=2
Бинарный поиск выгоден тем, что он удачно использует информацию о том, что массив отсортирован. Он может спокойно выбросить (не исследовать) часть в которой точно нет необходимых данных.